Abstract
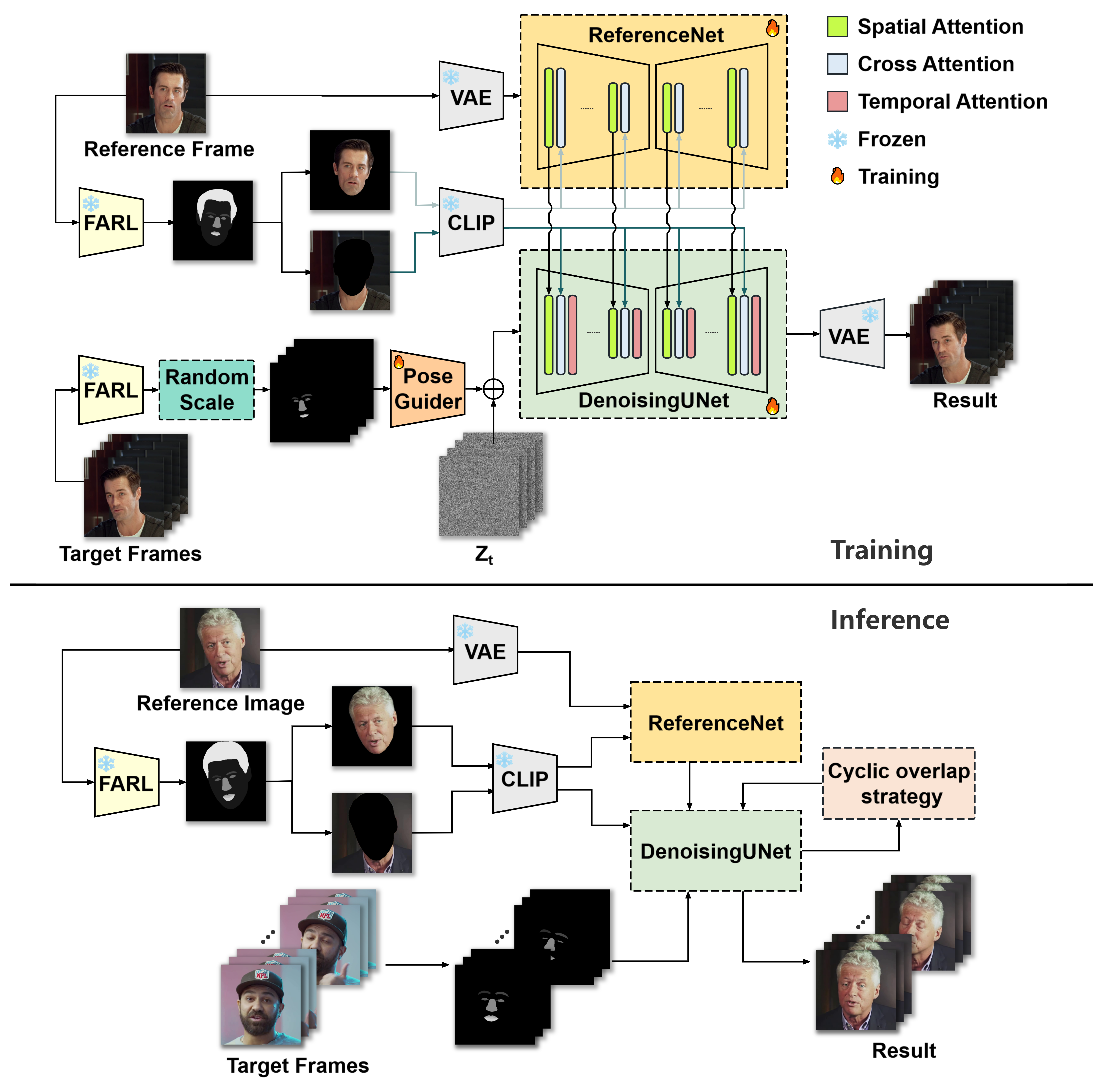
Portrait animation aims to transfer the facial expressions and movements of a target character onto a reference character. This task has two primary requirements: accurately transferring motion and expressions while fully preserving the reference portrait's identity features. We introduce Vividportraits, a diffusion-based model designed to effectively meet these requirements. In contrast to existing methods that rely on sparse representations such as facial landmarks, our approach leverages facial parsing maps for motion guidance, enabling a more precise conveyance of subtle expressions. A random scaling technique is applied during training to prevent the model from internalizing identity-specific features from the driving images. Additionally, we conduct foreground-background segmentation on the reference portrait to reduce data redundancy. The long-video generation process is refined to enhance consistency across extended sequences. Our model, exclusively trained on public datasets, demonstrates superior performance relative to current state-of-the-art methods, with a significant improvement of 8% in expression metric.